While We're Measuring Developer Productivity, Won't Someone Think of the Data Engineers?
Nicole Forsgren just dropped a new book, and I absolutely CONSUMED it. It's called Frictionless: seven steps to help engineering teams move faster in the age of AI. Forsgren created DORA. She created SPACE. She wrote Accelerate, the book that fundamentally changed how we measure engineering performance. When Forsgren talks about engineering velocity, you listen.
And, I hope I'm not oversimplifying, but my biggest take away is that "Most productivity metrics are systematically misleading."
Lines of code? Blown away by AI. Deployment frequency? Useful for assessing pipeline health, but disconnected from whether your team is building the right things. Her three pillars of developer experience:
- Flow state - "Developers who had a significant amount of time carved out for deep work felt 50% more productive, compared to those without dedicated time."
- Cognitive load - "Developers who report a high degree of understanding with the code they work with feel 42% more productive than those who report low to no understanding."
- Feedback loops - "Developers who report fast code review turnaround times feel 20% more innovative compared to developers who report slow turnaround times."
These represent a profound shift from output metrics to experience metrics.
And this resonates with me deeply. But I keep returning to one question.
Where are the data engineers in this conversation?
The Invisible Discipline
Software engineers have VS Code. Designers have Figma. Product managers have Linear. Analysts have Excel.
Data engineers have... YAML files. And hope.
While the industry has spent a decade obsessing over developer experience - building smarter IDEs, better autocomplete, faster CI - data engineering remains operationally primitive. The Anaconda 2024 State of Data Science found that data professionals spend 39% of their time on data prep and cleansing alone. That's more than model training, model selection, and deployment combined.
The same discipline responsible for the data that powers every AI model, every dashboard, every business decision is operating with less tooling sophistication than a junior React developer.
Forsgren's framework emphasizes fast feedback loops. She emphasizes flow state. She emphasizes reducing cognitive load so engineers can focus on innovation instead of plumbing.
Data engineers have none of this.
Working in the Dark
Let me walk you through how a data engineer actually works in 2025:
- Write a pipeline configuration
- Deploy it to Airflow or Dagster or whatever orchestrator you've standardized on
- Wait for the scheduler
- Get one of...
- Cryptic errors in a log somewhere
- Discover that you didn't include a python dependency
- Correlate timestamps across three different systems
- Guess at what went wrong
- Try to fix and it works locally (kind of)
- Redeploy
- Repeat until something works
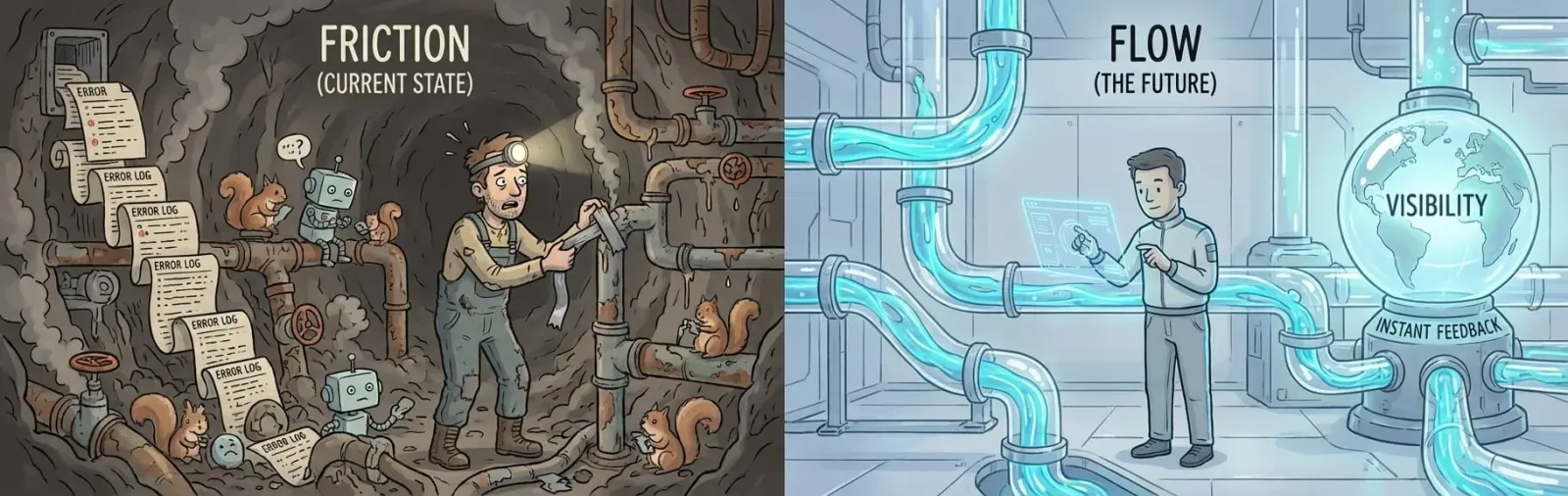
This isn't engineering. This is archaeology. You're reconstructing meaning from fragments - stack traces, partial outputs, timestamp correlations - hoping to divine what your data actually looks like at each stage.
Coralogix reports that developers spend up to 75% of their time debugging: roughly 1,500 hours per year. For data engineers, that number feels conservative. When your feedback loop is measured in minutes or hours instead of milliseconds, every debugging session becomes an exercise in professional gaslighting.
Was my regex wrong? Did the schema change upstream? Is this a type mismatch or an encoding issue? Is the data actually null, or did something fail silently three stages ago?
If say you haven't had a situation where someone said "Wait a second, this data hasn't been flowing for two weeks, why didn't we know that?", I don't believe you. BECAUSE EVERYONE HAS.
The data itself answers all these questions. But you can't see the data. You can only see the errors after the damage cascades through your entire pipeline.
The Cognitive Load Catastrophe
In her research, Forsgren identifies cognitive load as a primary predictor of engineering effectiveness. When cognitive load is high, flow state becomes impossible. When feedback loops are slow, cognitive load compounds.
Data engineers operate at maximum cognitive load by default.
They hold entire data models in memory. They mentally simulate how transformations will behave across edge cases they haven't seen. They predict how upstream schema changes will cascade through pipelines they can't visualize. A CrowdFlower survey found that data scientists considered cleaning and organizing data the most boring and least enjoyable part of their work ... yet it consumed the majority of their time.
This isn't a skills gap. This is a tools gap.
Think about it in manufacturing terms. Imagine running an assembly line where you can't see the product until it reaches the end. You hear a grinding noise somewhere in the middle, but you can't stop the line to inspect. You can only wait for a defective product to emerge, then work backward to guess which machine caused it.
That's data engineering today. The feedback loop is structurally broken.
The Business Case for Fixing This
Splunk's 2024 research calculated that unplanned downtime costs Global 2000 companies $400 billion annually; that makes up roughly 9% of profits. The ITIC 2024 survey found that 41% of enterprises estimate hourly downtime at $1 million to $5 million.
Data pipeline failures are a primary vector for this downtime. When a dashboard shows the wrong number, when an ML model trains on corrupted data, when a report goes out with last week's figures, these aren't just engineering problems. They're business catastrophes that erode stakeholder trust and consume engineering hours in firefighting.
Gartner predicts that by 2026, 50% of enterprises with distributed data architectures will have adopted data observability tools, up from less than 20% in 2024. That adoption curve tells you something: organizations are recognizing that you can't manage what you can't see.
Yet most data observability tools today operate ex-post. They alert you after the pipeline has failed. After the bad data has propagated. After the report has gone out. That's better than nothing, but it's not the same as seeing your data as you work with it.
What Would "Frictionless" Look Like for Data Engineers?
If we applied Forsgren's framework rigorously to data engineering, what would we build?
Instant feedback. Every modification to a transformation should immediately show the output. Not after deployment. Not after a 10-minute CI run.
Immediately.
Keystroke by keystroke.
The data is the interface.
Think about how dbt transformed SQL development by letting you preview transformations locally. Now extend that concept to every stage of every pipeline.
Errors that teach. No more NullPointerException at line 847 in AbstractTransformationFactory. Tell me: "Field 'user_id' is null on 3 records from the source table 'signups'. Here's where it originated. Here are your options." Tools like Great Expectations and Soda are moving in this direction and are making errors actionable rather than cryptic.
Schema awareness everywhere. The editor should know what fields exist. It should predict which functions make sense for each data type. It should warn you when you're about to drop a critical field. Modern IDEs have had this for decades. Data pipelines deserve the same intelligence.
Confidence before deployment. Let engineers freeze working transformations into tests. Let them fuzz pipelines with malformed data before production. Let them visualize shape changes across every stage so they know precisely what they're shipping.
This isn't aspirational. These capabilities exist in fragments across the ecosystem: Monte Carlo for observability, Elementary for dbt testing, OpenLineage for tracking dependencies. The challenge is integration. Data engineers shouldn't need to assemble six different tools and hope they interoperate.
And for those that say "there's already a tool and a job for that - it's VSCode/Jupyter and 'developer'", I agree! These folks ARE solving this problem today WITH those tools! HOWEVER, this is a different domain, and there are so many gaps that it almost doesn't matter. LET'S HELP.
The Productivity Metric That Actually Matters
Forsgren's core argument in Frictionless is that we should measure what matters to the business, not what's easy to count. Speed to value. Time to experiment. Velocity through the entire system.
For data engineering, the metric that matters is this: How long from opening a pipeline to knowing it works?
Right now, that's often hours. Sometimes days. Most of that time isn't spent building; it's spent in the dark, correlating logs, guessing at causes, waiting for orchestrators to cycle.
Imagine cutting that to minutes. Imagine seeing your data flowing through every transformation in real time. Imagine knowing before deployment whether your changes will break downstream consumers.
That's not a marginal improvement. That's a step-change in how data engineering operates. And it's the productivity gain we should be measuring—not lines of YAML or DAGs deployed.
COMMERCIAL INTERLUDE: 👋 We're From Expanso and We'd Like To Help 😄
At Expanso. we want to be part of the solution.
We realized that the biggest source of friction in data engineering isn't just bad syntax; it's physics.
Moving petabytes of data through fragile pipelines just to process it is the ultimate feedback loop killer. It creates latency, balloons costs, and forces engineers to manage complex "plumbing" rather than the logic itself.
By prioritizing Intelligent Data Pipelines that execute where you generate the data, we bring the processing to where the data lives, whether that’s on-prem, across multi-cloud, or at the edge.
This allows data engineers to bypass the "wait for transfer" phase entirely, collapsing the distance between code and execution. It’s about giving data teams the same immediate, frictionless agency that software engineers have enjoyed for years.
The Bottom Line
Forsgren's new book is about removing friction from engineering work. It's about recognizing that productivity isn't about coding faster; it's about reducing the cognitive overhead that prevents engineers from doing their best work.
Data engineers deserve this too.
They deserve to see their data. They deserve instant feedback. They deserve errors that explain rather than obscure. They deserve to work in a glass box instead of a black hole.
The industry has spent a decade optimizing developer experience for software engineers. We've built remarkable tools that give them immediate feedback, intelligent assistance, and confidence in what they're shipping.
Data engineers power the systems those developers depend on. They deserve the same respect.
The inspiration for this post came from Nicole Forsgren and Abi Noda's new book, Frictionless, go get it! . If you're thinking about engineering productivity - and given that downtime costs $400 billion annually, you should be - read it.
Want to learn how intelligent data pipelines can reduce your AI costs? Check out Expanso. Or don't. Who am I to tell you what to do.*
NOTE: I'm currently writing a book based on what I have seen about the real-world challenges of data preparation for machine learning, focusing on operational, compliance, and cost. I'd love to hear your thoughts!